我这个对话其实很简洁,因为我的工作区,设置了“Rule”如图:
我这个对话其实很简洁,因为我的工作区,设置了“Rule”如图:
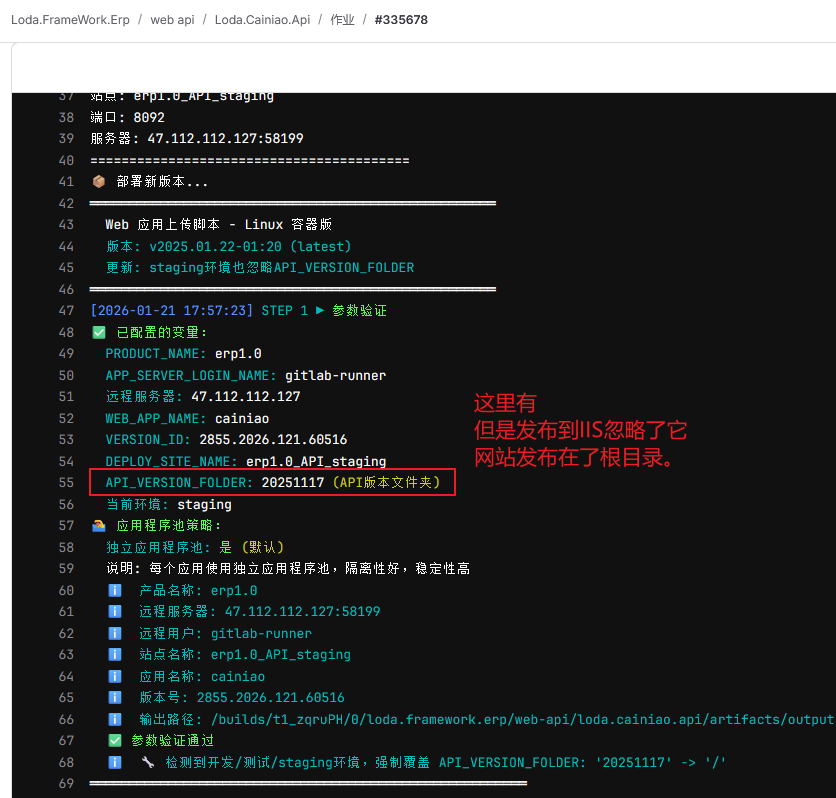
从控制台输出看来,staging阶段的发布,忽略了API_VERSION_FOLDER:
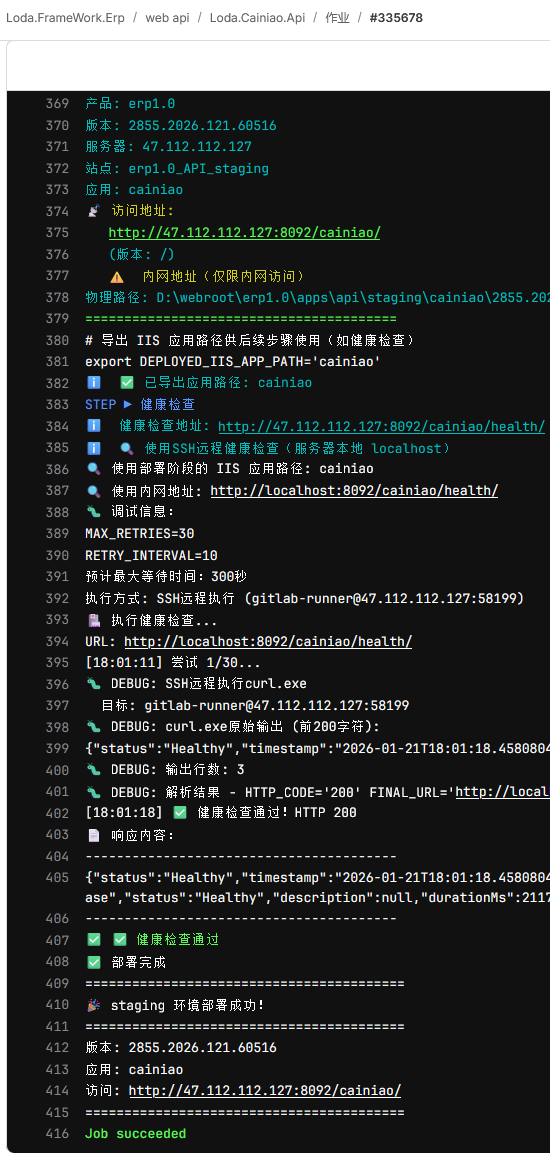
不急,请为我补充文档后一起签入。
我来搜索staging阶段发布web api相关的配置,了解API_VERSION_FOLDER的使用情况。
让我先读取更多相关文件,了解API_VERSION_FOLDER的完整使用逻辑。
理解了。需要让staging环境的web api部署也忽略API_VERSION_FOLDER。
关键代码在upload-web.sh第473-480行:
# 环境特定配置覆盖
# 强制覆盖开发和测试环境的API版本文件夹设置
DEPLOY_ENV="${DEPLOY_ENV_NAME:-$CURRENT_ENV}"
if [[ "$DEPLOY_ENV" == "development" ]] || [[ "$DEPLOY_ENV" == "dev" ]] || [[ "$DEPLOY_ENV" == "test" ]]; then
if [[ "$API_VERSION_FOLDER" != "/" ]]; then
info "🔧 检测到开发/测试环境,强制覆盖 API_VERSION_FOLDER: '$API_VERSION_FOLDER' -> '/'"
export API_VERSION_FOLDER="/"
fi
fi
目前只覆盖dev/development/test,需要加入staging。
确认需求:staging环境的web api是否需要额外判断TARGET_FRAMEWORK(只针对.NET Framework 4.8),还是所有staging的web api都忽略API_VERSION_FOLDER?
修改完成。现在更新脚本版本信息:
修改完成。
文件:@X:\gitlab\loda.online\server\gitlab\gitlab-runner\gitlab-runner-docker\srv\scripts\upload-web.sh
改动:
staging加入条件判断dev/development/test/staging环境都会强制将API_VERSION_FOLDER覆盖为/v2025.01.22-01:20cd "X:\gitlab\loda.online\server\gitlab\gitlab-runner\gitlab-runner-docker"
git add srv/scripts/upload-web.sh
git commit -m "LT-133: staging环境web api忽略API_VERSION_FOLDER"
git push
我要修改一个功能:staging阶段发布的web api,要忽略API_VERSION_FOLDER
KEY是LT-133
目前的这个web api,特指发布到IIS的基于.NET Framework 4.8的web api项目。
《Vibe Coding 实战规范(工程向 · v1.0)》
这不是宣传稿,是工程规范,是你可以拿去:
适用对象:全体程序员 / 架构师 / 技术负责人
目标:提升整体工程效率、系统质量与工程幸福感
人负责决策,AI负责实现;人对结果负责,AI不背锅。

你必须亲自完成:
 任何“我没看,是 AI 写的”都不可接受
任何“我没看,是 AI 写的”都不可接受

AI 被允许、且鼓励用于:
AI 是“超级实习生 + 编译器 + 搜索引擎”的合体
任何功能开始前,至少写清楚以下 4 点(可 10 行内):
## Intent
- 我要解决什么问题?
- 为什么现在要做?
## Scope
- 本次做什么
- 明确不做什么
## Constraints
- 技术约束(语言/框架/版本)
- 性能/安全/兼容性要求
## Done Definition
- 什么状态算“完成”
这是给 AI 的,也是给未来的你和同事的。
 不推荐:
不推荐:
“帮我写一个 XXX 的代码”
推荐:
“在以下约束下,设计一个可扩展方案,先给结构,再给示例实现”
“这个模块未来可能要支持多租户,请预留扩展点”
必须人工检查的点:
AI 的第一版,默认是“草稿”。
Vibe Coding 的核心优势:
一句标准心态:
“这版不对,换个 vibe 再来一轮。”
禁止:
要求:
以下至少满足一项:
这不是给领导看,是给未来维护的人看。
“这行代码是不是你亲手写的?”
是否符合设计意图
是否符合系统长期演进方向
是否存在被 AI 忽略的边界条件
是否可以更简单
一句话总结:
Review 的对象是“方案质量”,不是“作者是谁”。
Vibe Coding 不会降低要求,反而更高:
你需要提升的是:
不会思考的人,用 AI 只会更快地产生垃圾。
 “AI 写的,应该没问题”
“AI 写的,应该没问题”
“先跑起来再说”
“我看不懂但能用”
“反正不是我写的”
责任永远属于合并代码的人。
不是为了:
而是为了:
Vibe Coding 不是捷径,而是把工程师从“体力劳动”中解放出来的一种新分工方式。
我们不降低质量标准,只提升效率上限。
AI 不是替代者,而是放大器。
最终负责系统成败的,仍然是人。
适用人群:
对 AI 写代码持怀疑态度 / 有经验的程序员 / 担心被“降级”的同事目标:
消除误解,而不是强行说服
短答:不是。
长答:
Vibe Coding 的核心不是“谁敲代码”,而是:
谁负责判断,谁承担责任。
在 Vibe Coding 里:
如果你只是把需求丢给 AI,不看、不改、不负责——
那不是 Vibe Coding,那是失职。
一句话反驳:
“你让 IDE 自动补全代码,也没说你在‘偷懒’。”
这是一个“阶段性正确,但方向性错误”的判断。
事实是:
Vibe Coding 的正确用法是:
你不是“相信 AI”,而是“驱动 AI”。
反问一句就够了:
“你现在写的第一版代码,是完美的吗?”
恰恰相反。
在 Vibe Coding 时代:
AI 不会替你判断:
结论:
Vibe Coding 会淘汰“只会写代码但不懂系统的人”,
而不是淘汰真正的工程师。
这是一个非常典型、但方向完全相反的担忧。
真实情况是:
| 人的类型 | 在 Vibe Coding 下 |
|---|---|
| 架构能力强 | 输出速度指数级提升 |
| 会拆问题 | 能快速驾驭 AI |
| 只会照抄 | 更快暴露问题 |
| 不会表达需求 | AI 也帮不了 |
AI 放大的不是“努力”,而是“能力结构”。
一句话结论:
差距不会消失,只会被加速放大。
不会,而且你练的东西终于值钱了。
过去:
现在:
代码能力 ≈
你过去十年练的那些:
这些,AI 给不了新人。
这是一个必须正面回答的问题。
我们的立场是:
如果只是为了裁人,那根本不需要 Vibe Coding。
Vibe Coding 的真实目标是:
一句现实但诚实的话:
“不拥抱 AI 的团队,不会因为拒绝而变安全。”
不需要,也不允许“一刀切”。
推荐的低风险起点:
禁止的做法:
因为它本质上是在说一句话:
“程序员不应该把生命浪费在 AI 已经能干得更快的事情上。”
Vibe Coding 不是命令,也不是 KPI。
它是一种选择:
最近在推动 Vibe Coding 的过程中,有同事认真地问我一句:
“什么是 Vibe Coding?”
这个问题本身,非常好。
说明大家不是盲从,而是在思考:这是不是又一个管理层发明的流行词?
我的结论很明确:
Vibe Coding 不是概念包装,而是一次程序员生产方式的代际升级。
一句话版本:
Vibe Coding = 人负责“方向、判断、品味”,AI负责“实现、推演、补全”。
不是:
而是:
你不再从「敲每一行代码」开始,而是从:
开始。
需求 → 设计 → 写代码 → 查文档 → Debug → 改 → 再 Debug
特点:
意图 → 结构 → 约束 → AI 实现 → 人校验 → 快速迭代
变化在于:
| 维度 | 传统 Coding | Vibe Coding |
|---|---|---|
| 人的角色 | 代码工人 | 架构师 / 决策者 |
| 时间消耗 | 写 & 查 | 想 & 验 |
| 重复劳动 | 人反复做 | AI 反复做 |
| 出错成本 | 高 | 低(重来几乎无成本) |
| 思考层级 | 语法级 | 系统级 |
你不是写得更少了,而是站得更高了。
今天真正稀缺的不是:
而是:
这些,AI 很难替代;但写代码本身,AI 非常擅长。
现实是:
Vibe Coding 带来的不是“偷懒”,而是:
写废了?删了重来。
方案不对?换个 vibe 再跑一版。
一个常见误解是:
“AI 会让大家水平变得一样。”
恰恰相反。
在 Vibe Coding 下:
AI 不会帮你做“判断”,只会放大你的“判断”。
说一句实在话:
这是近十年来,第一次真正“站在程序员这边”的技术浪潮。
它意味着:
它也意味着:
不是口号,而是明确方向:
AI 是工具,不是权威;人是最终责任人。
如果你问我一句:
“Vibe Coding 值不值得学?”
我的回答是:
这不是‘值不值得’,而是‘早一点,还是晚一点’的问题。
我们选择现在开始,是因为: